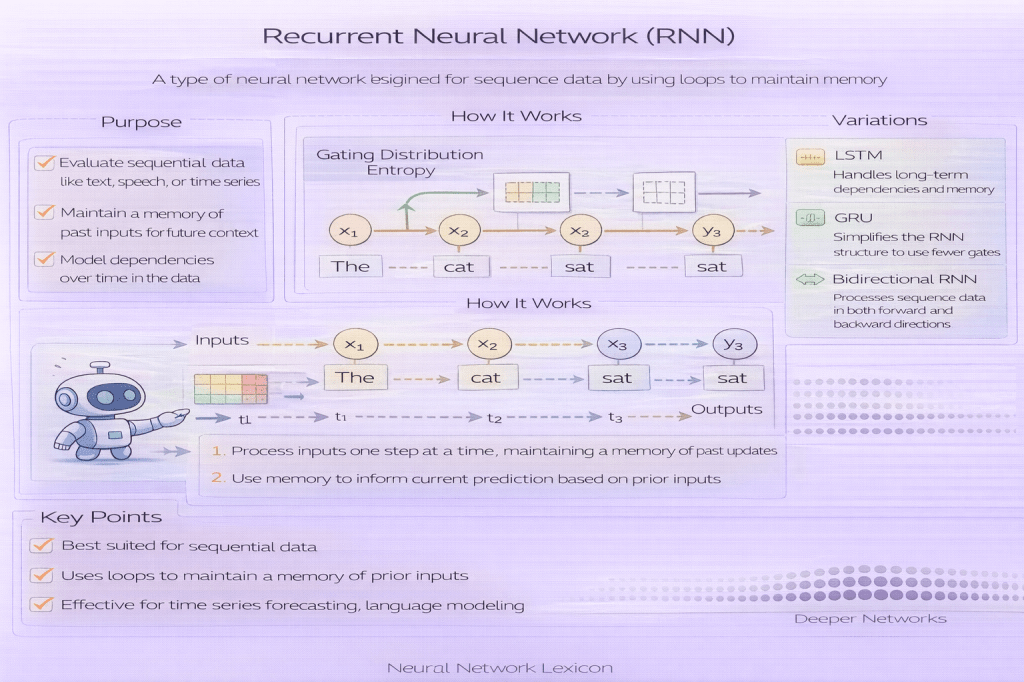
Short Definition
A Recurrent Neural Network (RNN) is a neural network architecture designed to process sequential data by maintaining a hidden state that evolves over time.
Definition
A Recurrent Neural Network (RNN) is a class of neural architectures that processes input sequences step-by-step while carrying forward a hidden state that summarizes previous inputs. Unlike feedforward networks, RNNs reuse the same parameters across time steps, enabling them to model temporal dependencies and order-sensitive patterns.
Memory is embedded in recurrence.
Why It Matters
Many real-world data types are sequential:
- text and language
- time series
- audio signals
- event logs
- sensor streams
RNNs were among the first architectures designed explicitly for sequence modeling.
Core Mechanism
At each time step ( t ):
h_t = f(W_x x_t + W_h h_{t-1} + b)
Where:
- xt = input at time t
- ht−1 = previous hidden state
- ht = updated hidden state
- Wx,Wh = shared weight matrices
The same weights are reused across time.
Minimal Conceptual Illustration
x₁ → [RNN] → h₁x₂ → [RNN] → h₂x₃ → [RNN] → h₃Or unrolled:
x₁ → (Cell) → h₁ → (Cell) → h₂ → (Cell) → h₃Recurrence creates temporal memory.
Key Characteristics
- Parameter sharing across time
- Hidden state carries history
- Sequence-length flexibility
- Order sensitivity
Time becomes a dimension of computation.
Training RNNs
RNNs are trained using Backpropagation Through Time (BPTT), where gradients are propagated backward across multiple time steps.
This creates long dependency chains.
Vanishing and Exploding Gradients
Classic RNNs suffer from:
- Vanishing gradients (long-term memory loss)
- Exploding gradients (unstable updates)
This limits their ability to model long-range dependencies.
Relationship to Gating Mechanisms
Architectures like:
- LSTM (Long Short-Term Memory)
- GRU (Gated Recurrent Unit)
introduce gating to control information flow and mitigate gradient problems.
Gating stabilizes memory.
Applications
RNNs have been used for:
- language modeling
- machine translation
- speech recognition
- financial forecasting
- anomaly detection in time series
Sequence modeling defined their dominance.
Limitations
Compared to modern architectures:
- Training is sequential (limited parallelism)
- Long-term dependency modeling is difficult
- Transformers outperform RNNs on many NLP tasks
Parallel attention replaced recurrence in many domains.
RNN vs Transformer
- RNN: sequential state propagation
- Transformer: attention over entire sequence
RNNs scale in time; transformers scale in parallel.
Practical Considerations
RNNs remain useful when:
- sequence length is moderate
- memory footprint must be small
- streaming inference is required
- low-latency sequential updates are needed
Not obsolete, but specialized.
Common Pitfalls
- ignoring gradient clipping
- using vanilla RNNs for long sequences
- forgetting hidden state initialization
- mismanaging variable-length sequences
Recurrence must be handled carefully.
Summary Characteristics
| Aspect | RNN |
|---|---|
| Architecture type | Sequential |
| Memory mechanism | Hidden state |
| Training method | BPTT |
| Main limitation | Vanishing gradients |
| Modern alternative | Transformers |
Related Concepts
- Architecture & Representation
- Sequence Modeling
- Backpropagation Through Time (BPTT)
- Vanishing Gradients
- Exploding Gradients
- Gating Mechanisms
- LSTM
- GRU
- Transformers
