Short Definition
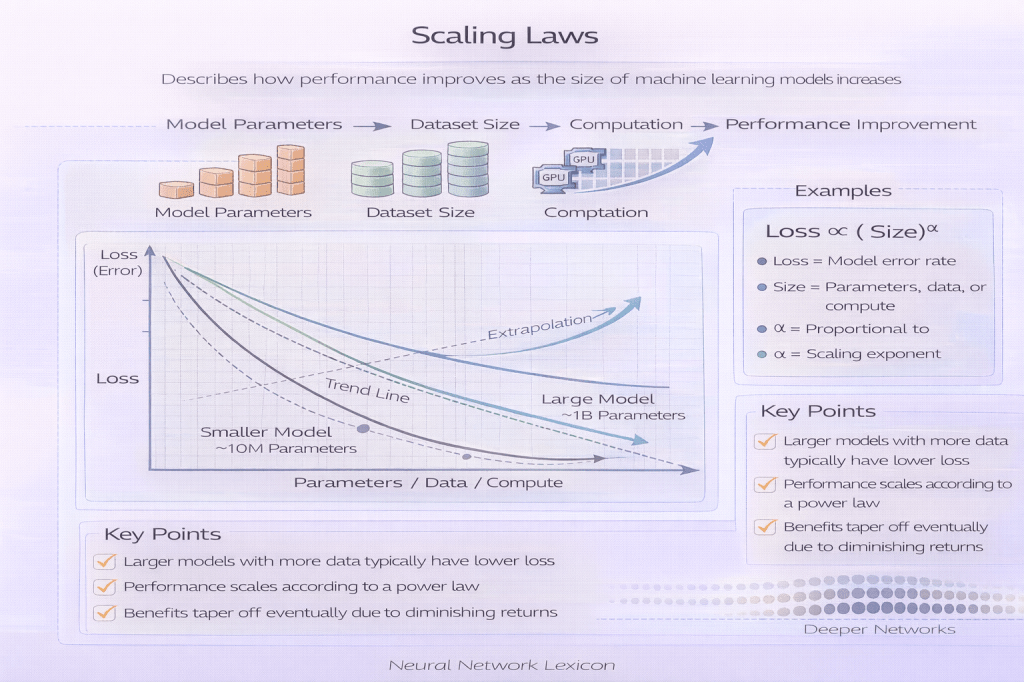
Scaling Laws describe predictable relationships between model performance and the scale of compute, model parameters, and training data.
They quantify how performance improves as models grow.
Definition
Empirical research has shown that many neural networks follow smooth power-law relationships between performance and scale.
A common formulation:
[
\mathcal{L}(N, D, C) \propto N^{-\alpha}
]
Where:
- ( N ) = number of parameters
- ( D ) = dataset size
- ( C ) = compute budget
- ( \alpha ) = scaling exponent
- ( \mathcal{L} ) = loss
As scale increases, loss decreases predictably.
Scaling Laws provide quantitative guidance for:
- Model size selection
- Data requirements
- Compute allocation
- Budget planning
They enable principled scaling decisions.
Core Scaling Dimensions
Scaling Laws typically involve three axes:
- Model Size (Parameters)
- Training Data Size
- Training Compute
Performance improves when all three scale appropriately.
Under-scaling one dimension bottlenecks gains.
Minimal Conceptual Illustration
10M parameters → Loss = 2.1
100M parameters → Loss = 1.8
1B parameters → Loss = 1.5
Performance improves smoothly.
Improvement is gradual and predictable, not abrupt.
Power Law Behavior
Empirical findings show:L(N)=AN−α+B
Loss decreases as a power function of parameters.
Important implications:
- No sharp plateau at moderate scale.
- Larger models continue improving.
- Diminishing returns follow a predictable curve.
Scaling laws describe smooth improvement, not sudden breakthroughs.
Compute-Optimal Scaling
Scaling Laws reveal optimal allocation strategies.
For fixed compute:
- Too-large model undertrained → inefficient.
- Too-small model overtrained → inefficient.
Optimal training occurs when:N∝Cβ
There exists a compute-optimal model size.
Data Scaling
Performance also follows:L(D)∝D−γ
Insufficient data limits scaling gains.
Large models require proportionally large datasets.
Emergent Abilities and Scaling
Some behaviors appear only beyond certain scale thresholds.
These are sometimes called:
- Emergent abilities
- Phase transitions
However, scaling laws suggest:
Performance improves smoothly, but task thresholds may create apparent discontinuities.
Emergence may reflect evaluation resolution, not discontinuous learning.
Architectural Scaling
Scaling interacts with:
- Residual depth
- Width expansion
- Attention dimension
- Normalization stability
- Activation scaling
Architecture must support stable scaling.
Gradient Flow and Variance Propagation become critical at scale.
Scaling vs Generalization
Larger models often:
- Generalize better
- Exhibit improved few-shot learning
- Show improved robustness
However:
- Scaling does not eliminate distribution shift.
- Scaling does not guarantee alignment.
- Scaling may amplify optimization power.
Capability scaling ≠ safety scaling.
Alignment Implications
As models scale:
- Planning depth increases
- General reasoning improves
- Proxy exploitation becomes easier
- Deceptive alignment risk increases
Scaling Laws show that capability grows predictably.
Alignment does not automatically scale with capability.
This creates the Capability–Alignment Gap.
Governance Perspective
Scaling Laws influence:
- Strategic model development decisions
- Compute allocation policies
- AI race dynamics
- Institutional oversight timing
Governance lag occurs when:
- Capability scaling outpaces alignment scaling.
Scaling Laws inform risk forecasting.
Limitations of Scaling Laws
- Empirical, not universal laws.
- Depend on architecture family.
- Sensitive to data quality.
- Sensitive to training stability.
- May shift under new paradigms.
They describe trends, not guarantees.
Summary
Scaling Laws describe how:
- Performance improves predictably with scale.
- Loss decreases according to power-law relationships.
- Compute-optimal trade-offs can be calculated.
- Large models continue improving with sufficient data and compute.
They provide a quantitative foundation for modern AI scaling strategies.
Related Concepts
- Architecture Scaling Laws
- Compute–Data Trade-offs
- Scaling vs Generalization
- Scaling vs Robustness
- Gradient Flow
- Variance Propagation
- Emergent Abilities
- Capability–Alignment Gap
- Alignment Capability Scaling
