Short Definition
Resampling techniques modify how data samples are selected to improve learning and evaluation.
Definition
Resampling techniques are methods that alter the composition of a dataset by reselecting, duplicating, or removing samples to address issues such as class imbalance, limited data, or high variance in evaluation. These techniques operate at the data level rather than changing model architecture or optimization.
Resampling reshapes the effective data distribution seen by the model.
Why It Matters
Real-world datasets are often imbalanced, noisy, or small. Resampling can help stabilize training, improve minority-class learning, and produce more reliable evaluation metrics when used appropriately.
However, improper resampling can introduce bias or leakage.
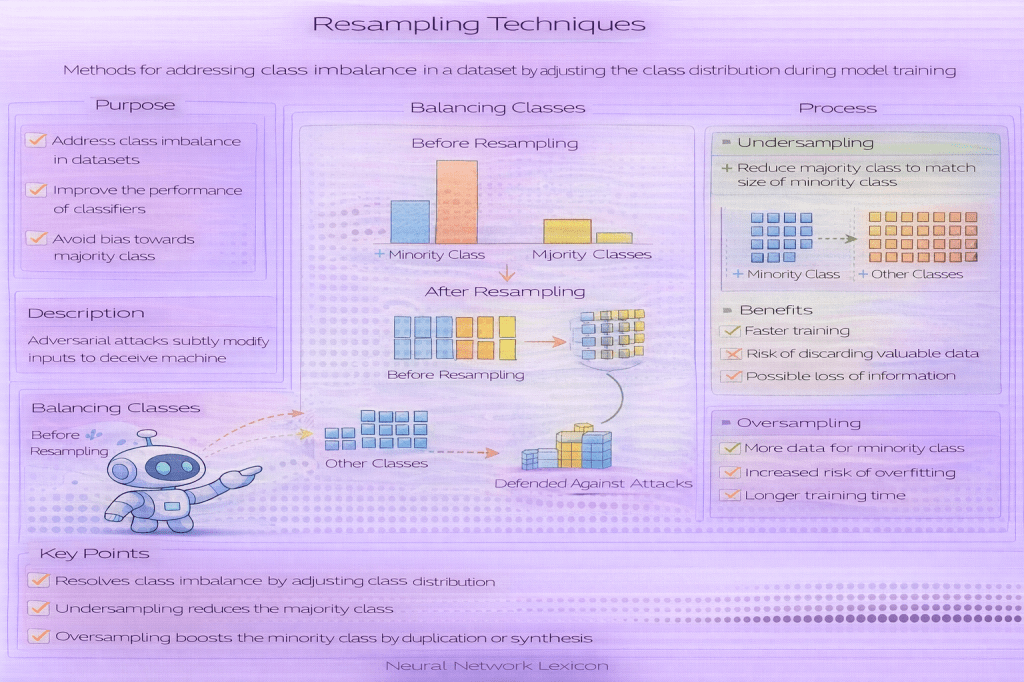
Common Types of Resampling Techniques
Widely used approaches include:
- Oversampling: duplicating or synthesizing minority-class samples
- Undersampling: removing samples from majority classes
- Bootstrap sampling: sampling with replacement
- Stratified resampling: preserving subgroup proportions
- Synthetic sampling: generating new samples (e.g., SMOTE-like methods)
Each method has different trade-offs.
How Resampling Affects Learning
- changes class frequency and gradient influence
- alters decision boundaries
- affects variance and bias trade-offs
- may impact probability calibration
Resampling optimizes learning dynamics, not ground truth.
Minimal Conceptual Example
# conceptual illustrationresampled_data = resample(original_data, strategy="oversample_minority")Resampling vs Reweighting
- Resampling: changes the dataset itself
- Reweighting: changes the loss contribution of samples
Both aim to address imbalance but operate differently.
Common Pitfalls
- resampling before train/test splitting
- applying resampling to validation or test sets
- oversampling leading to overfitting
- ignoring distribution mismatch with deployment data
Resampling must respect evaluation boundaries.
Relationship to Class Imbalance
Resampling is a common response to class imbalance, especially when minority classes are rare. It improves representation during training but does not change the underlying real-world label distribution.
Evaluation should reflect true deployment frequencies.
Relationship to Generalization
Resampling can improve in-distribution generalization for underrepresented classes but may harm calibration or performance under distribution shift. Its effects must be validated carefully.
Related Concepts
- Data & Distribution
- Class Imbalance
- Stratified Sampling
- Label Distribution
- Cost-Sensitive Learning
- Generalization
- Evaluation Metrics
