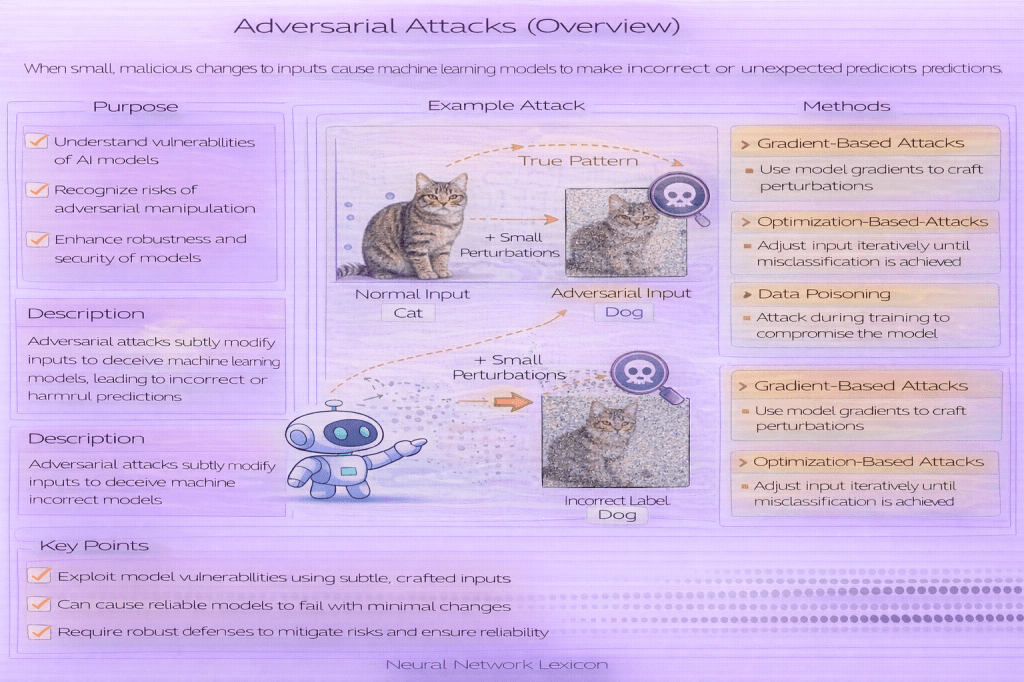
Short Definition
Adversarial attacks are intentional strategies designed to cause machine learning models to make incorrect predictions.
Definition
Adversarial attacks are methods by which an attacker deliberately manipulates inputs, model access, or evaluation conditions to induce model failure. Unlike natural errors caused by noise or distribution shift, adversarial attacks are purposeful and worst-case in nature.
They are used both offensively—to exploit model weaknesses—and defensively—to study robustness and failure modes.
Why It Matters
Standard evaluation assumes benign inputs drawn from a fixed distribution. Adversarial attacks violate this assumption and reveal vulnerabilities that remain hidden under normal testing.
Understanding adversarial attacks is critical for:
- assessing real-world reliability
- deploying models in security-sensitive settings
- designing robust and trustworthy systems
- avoiding overconfidence in benchmark performance
Adversarial attacks show that high accuracy does not imply safety.
What Adversarial Attacks Exploit
Adversarial attacks typically exploit one or more of the following:
- fragile decision boundaries
- high-dimensional input spaces
- overconfident predictions
- misalignment between model features and human semantics
- access to gradient or output information
These weaknesses are structural, not implementation bugs.
Core Dimensions of Adversarial Attacks
Adversarial attacks are commonly categorized along several independent dimensions.
Attacker Knowledge
- White-Box Attacks: full access to model parameters and gradients
- Black-Box Attacks: no internal access; rely on queries or transferability
Attack Intent
- Targeted Attacks: force prediction into a specific class
- Untargeted Attacks: cause any incorrect prediction
Attack Timing
- Evasion Attacks: manipulate inputs at inference time
- Poisoning Attacks: corrupt training data (conceptual mention only, if added later)
Each dimension defines a different threat model.
Why Taxonomy Matters
Different attack types test different aspects of model robustness. A model robust to one class of attack may remain vulnerable to others.
Clear taxonomy prevents:
- overgeneralized robustness claims
- misleading evaluation results
- inappropriate defensive assumptions
Robustness is always relative to a threat model.
Relationship to Robustness
Adversarial attacks are not robustness themselves—they are tools for probing robustness.
They help answer:
- How brittle is the model?
- Where does it fail?
- Under what assumptions does it break?
Robustness must be evaluated against explicit attack assumptions.
Minimal Conceptual Example
# attacker objective (conceptual)maximize loss(model(input + perturbation), target)This objective highlights the adversarial nature: the attacker optimizes against the model.
Common Pitfalls
- Treating adversarial attacks as rare corner cases
- Evaluating robustness against a single attack type
- Assuming noise robustness implies adversarial robustness
- Ignoring confidence and calibration failures under attack
Related Concepts
- Adversarial Examples
- Model Robustness
- White-Box Attacks
- Black-Box Attacks
- Targeted Attacks
- Untargeted Attacks
- Evasion Attacks
