Short Definition
Adversarial training improves robustness by training a model on adversarially perturbed inputs.
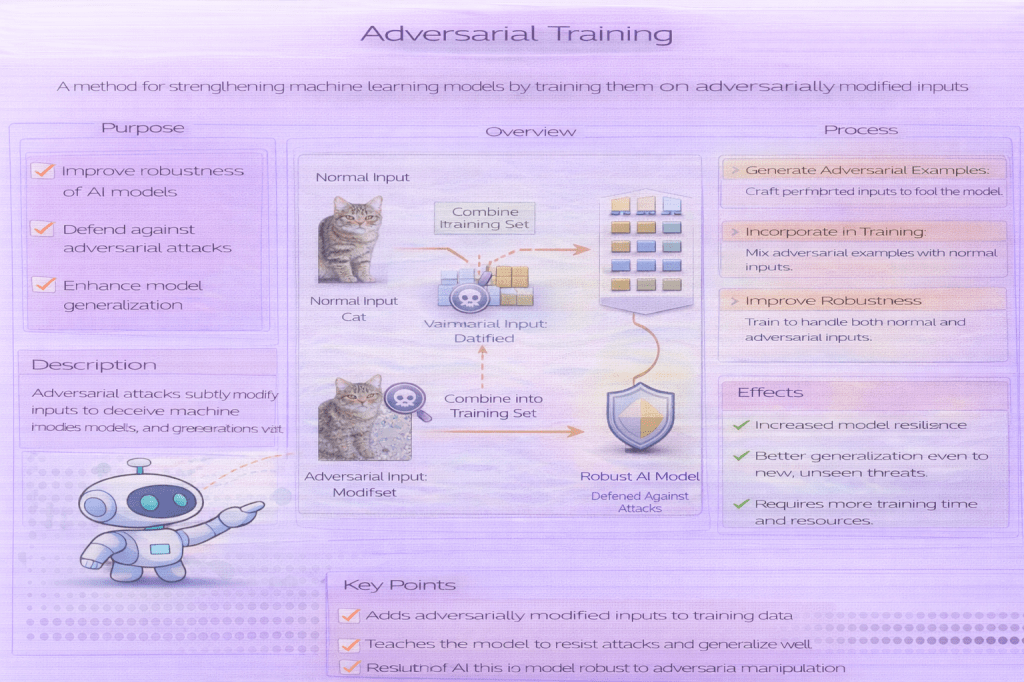
Definition
Adversarial training is a defensive training strategy in which adversarial examples are generated during training and included in the training process. The model is optimized not only to perform well on clean inputs, but also to maintain correct predictions under specified adversarial perturbations.
This approach reframes training as a worst-case optimization problem within a defined threat model.
Why It Matters
Standard training optimizes average-case performance and leaves models vulnerable to worst-case inputs. Adversarial training directly addresses this gap by exposing the model to adversarial conditions during learning.
It is one of the most effective and widely studied defenses against adversarial attacks, though it introduces important trade-offs.
How Adversarial Training Works (Conceptually)
- Define a threat model (attack type, perturbation budget)
- Generate adversarial examples for training inputs
- Train the model to minimize loss on these adversarial inputs
- Repeat throughout training
The objective encourages stable predictions within the allowed perturbation region.
Effects of Adversarial Training
- Improves robustness within the defined threat model
- Reduces vulnerability to gradient-based attacks
- Often lowers accuracy on clean data
- Increases training time and computational cost
Robustness gains are threat-model specific.
Limitations
- Robustness does not generalize to unseen attack types
- Strong dependence on attack strength and assumptions
- Reduced clean accuracy is common
- High computational overhead
Adversarial training is not a universal defense.
Minimal Conceptual Example
# conceptual training loopfor x, y in training_data: x_adv = generate_adversarial_example(model, x, y) update_model(model, x_adv, y)
Common Pitfalls
- Training against weak or unrealistic attacks
- Claiming general robustness from narrow threat models
- Ignoring clean-performance degradation
- Evaluating robustness with mismatched attacks
- Robustness claims must match the training assumptions.
Related Concepts
- Adversarial Attacks (Overview)
- Adversarial Examples
- Robustness Metrics
- Model Robustness
- White-Box Attacks
- Evasion Attacks
