Short Definition
Gradient Flow describes how gradients propagate backward through a neural network during training, determining whether learning signals remain stable, vanish, or explode across depth.
It governs trainability in deep networks.
Definition
Neural networks are trained using backpropagation.
Given a loss function ( \mathcal{L} ), gradients are computed as:
[
\frac{\partial \mathcal{L}}{\partial W_l}
]
These gradients depend on the chain rule:
[
\frac{\partial \mathcal{L}}{\partial x_0}
\prod_{l=1}^{L}
\frac{\partial x_l}{\partial x_{l-1}}
]
If this product:
- Shrinks toward zero → Vanishing gradients
- Grows uncontrollably → Exploding gradients
- Remains stable → Healthy gradient flow
Gradient Flow determines whether deep networks can learn effectively.
Why Gradient Flow Matters
Without stable gradient flow:
- Early layers do not update properly.
- Training stalls.
- Optimization becomes unstable.
- Deep architectures fail.
Most breakthroughs in deep learning were fundamentally about improving gradient flow.
Minimal Conceptual Illustration
Layer 1 → gradient = 1.0
Layer 2 → gradient = 0.8
Layer 3 → gradient = 0.64
Layer 4 → gradient = 0.51
…
Vanishing
OR
Layer 1 → 1.0
Layer 2 → 1.5
Layer 3 → 2.25
Layer 4 → 3.37
…
Exploding
Multiplicative chains amplify small deviations.
Mathematical Perspective
In deep networks:∂x0∂L=JLJL−1…J1
Where Jl is the Jacobian of layer l.
Gradient stability depends on:
- Singular values of Jacobians
- Spectral norms
- Weight scaling
- Activation function derivatives
If average singular value ≈ 1 → stable gradient flow.
Causes of Gradient Instability
1. Poor Initialization
Incorrect weight scaling causes exponential drift.
2. Activation Functions
- Sigmoid / tanh → saturation → small derivatives → vanishing gradients
- ReLU → better gradient preservation
3. Depth
More layers → more multiplicative Jacobians.
4. Lack of Residual Paths
Pure feedforward chains accumulate multiplicative error.
Mechanisms That Improve Gradient Flow
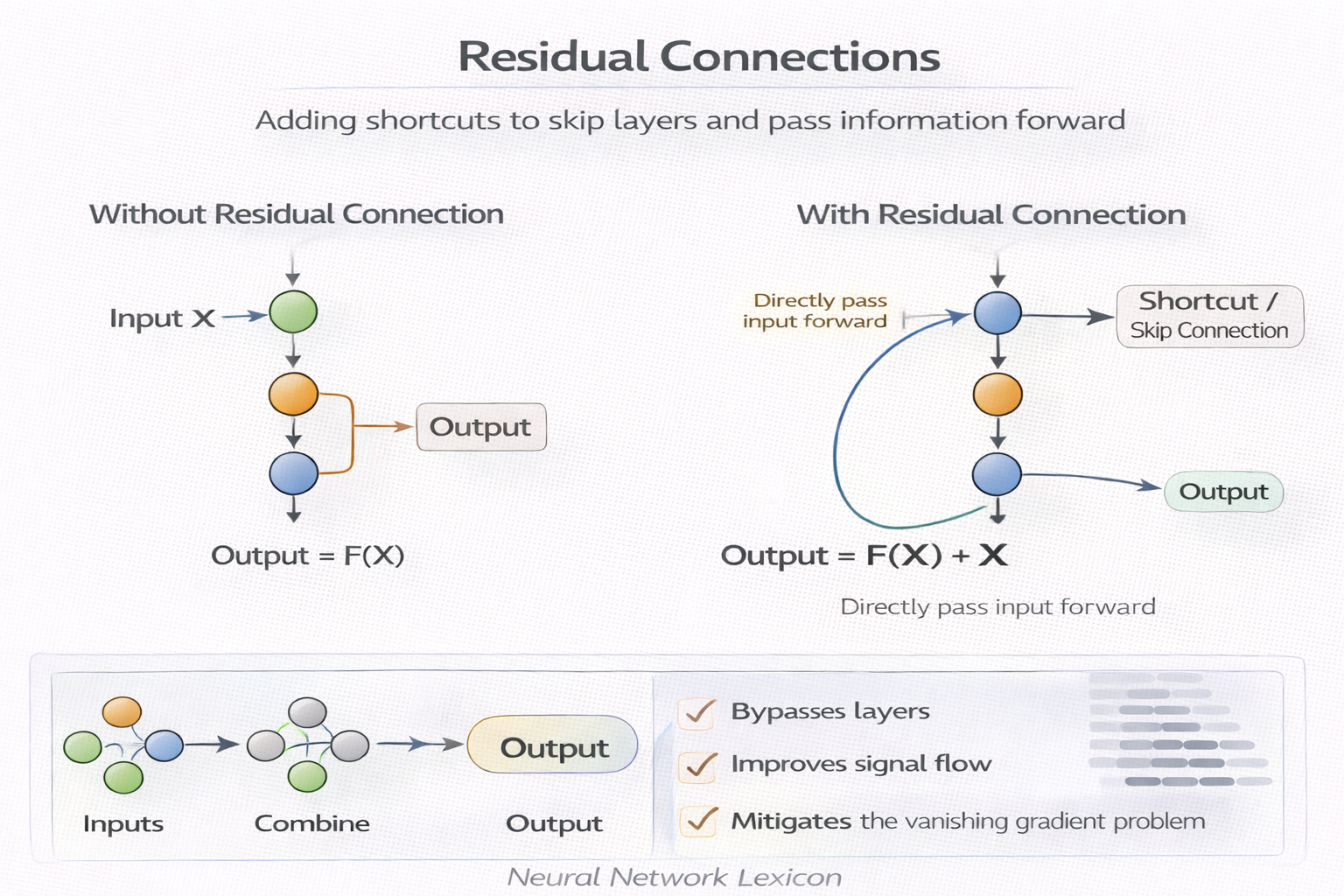
Residual Connections
xl+1=xl+f(xl)
Creates identity shortcut for gradients.
Major breakthrough in deep learning.
Normalization Layers
LayerNorm and BatchNorm stabilize activation magnitudes, improving backward stability.
Attention Scaling
Transformer scaling factor 1/d prevents gradient explosion.
Gradient Clipping
Explicitly limits gradient magnitude.
Relationship to Variance Propagation
Forward variance stability supports stable backward gradients.
Deep Signal Propagation Theory links:
- Activation variance
- Gradient singular values
- Dynamical isometry
Healthy forward signal often implies healthier gradient flow.
RNN and BPTT Context
Recurrent Neural Networks multiply the same weight matrix repeatedly:∂x0∂L=WTWT…WT
This caused early RNN training failures.
LSTM and GRU architectures were designed to preserve gradient flow over time.
Transformers and Gradient Flow
Transformers rely on:
- Pre-Norm residual blocks
- Residual scaling
- Careful initialization
- Attention scaling
Pre-Norm architecture improves gradient flow in very deep stacks.
Failure Modes
Poor gradient flow leads to:
- Slow convergence
- Training instability
- Depth limits
- Exploding training loss
- Model collapse
Many architectural innovations exist to stabilize gradient flow.
Scaling Perspective
As models scale in:
- Depth
- Width
- Parameter count
Gradient flow becomes more delicate.
Large models require precise scaling control.
Alignment & Governance Perspective
Stable gradient flow enables:
- Deeper models
- Higher capability scaling
- More complex reasoning
However, better gradient flow increases optimization power.
Stronger optimization can amplify:
- Reward hacking
- Goal misgeneralization
- Proxy exploitation
Optimization stability affects alignment dynamics.
Summary
Gradient Flow describes how learning signals propagate backward through deep networks.
Stable gradient flow:
- Enables deep learning.
- Prevents vanishing/exploding gradients.
- Is supported by residual connections, normalization, and scaling.
Deep architectures succeed because gradient flow is engineered carefully.
Related Concepts
- Vanishing Gradients
- Exploding Gradients
- Deep Signal Propagation Theory
- Variance Propagation in Deep Networks
- Residual Connections
- Weight Initialization
- Normalization Layers
- Backpropagation Through Time (BPTT)

{kind=link}
{kind=link}